Domain-Robust Visual Imitation Learning with Mutual Information Constraints
Accepted to ICLR2021: International Conference on Learning Representations
Edoardo Cetin Oya Celiktutan
Department of Engineering, King's College London
|
Abstract
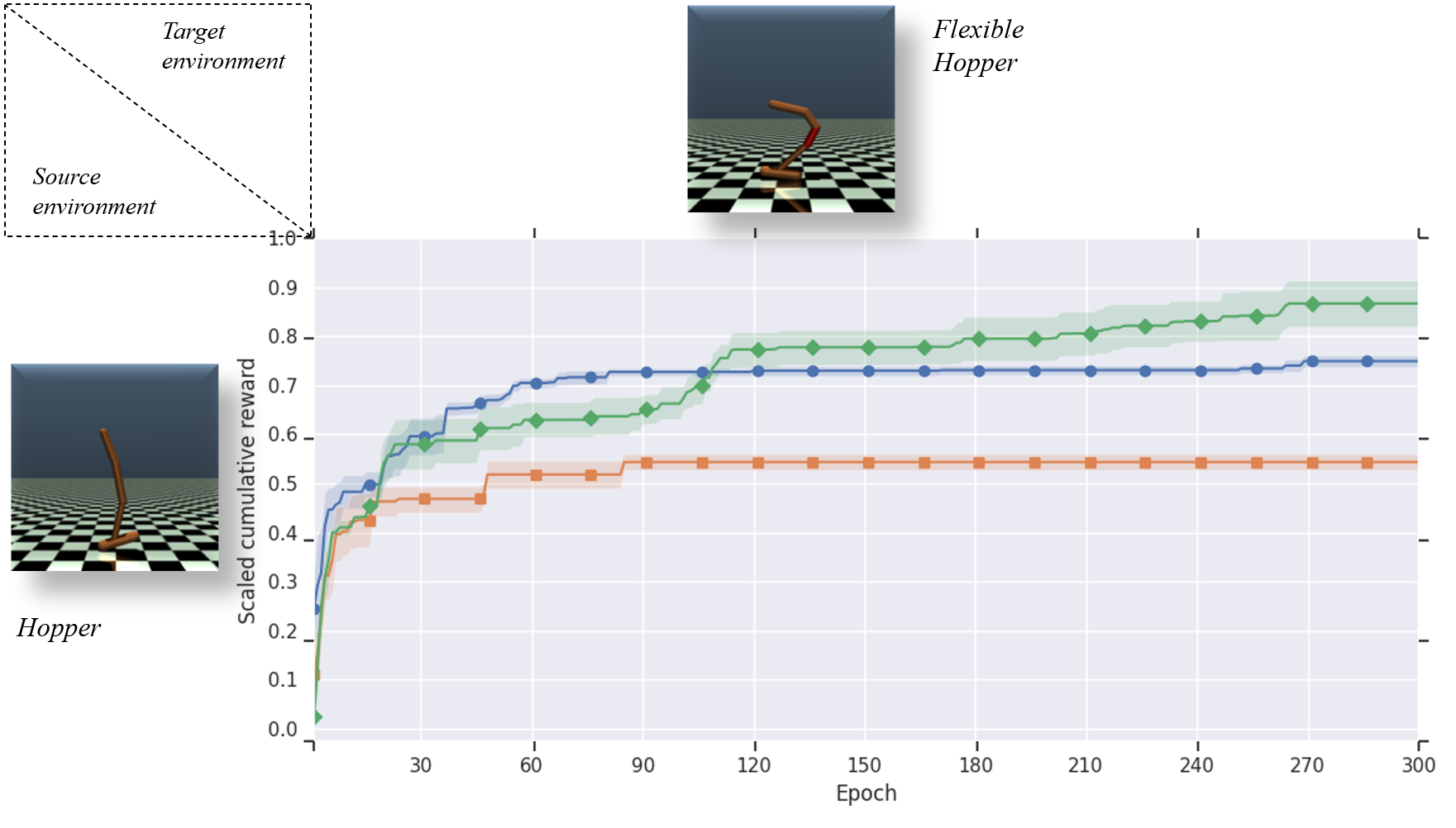
Human beings are able to understand objectives and learn by simply observing others perform a task. Imitation learning methods aim to replicate such capabilities, however, they generally depend on access to a full set of optimal states and actions taken with the agent's actuators and from the agent's point of view. In this paper, we introduce a new algorithm - called Disentangling Generative Adversarial Imitation Learning (DisentanGAIL) - with the purpose of bypassing such constraints. Our algorithm enables autonomous agents to learn directly from high dimensional observations of an expert performing a task, by making use of adversarial learning with a latent representation inside the discriminator network. Such latent representation is regularized through mutual information constraints to incentivize learning only features that encode information about the completion levels of the task being demonstrated. This allows to obtain a shared feature space to successfully perform imitation while disregarding the differences between the expert's and the agent's domains. Empirically, our algorithm is able to efficiently imitate in a diverse range of control problems including balancing, manipulation and locomotive tasks, while being robust to various domain differences in terms of both environment appearance and agent embodiment.
|
Paper: [PDF]
Code: [Details are coming soon! Stay tunned!]
|
Bibtex
@inproceedings{CetinCeliktutanICLR21,
author = {Cetin, Edoardo and Celiktutan, Oya},
booktitle = {International Conference on Learning Representations},
title = {Domain-Robust Visual Imitation Learning with Mutual Information Constraints},
year = {2021} }